Discovery, BDD’s foundation
Behavior Driven Development is an approach to software development that relies on creating a common understanding of the requirements through the use of real use case examples, thus ensuring that we are building the right thing.
Arguably the most important practice of BDD to reach this shared understanding is the Discovery part. In our last post, we presented what is BDD, how it works, and how we implemented it with our team at Jumia. This time around, we will deep dive into the Discovery practice and how we apply it, what are the benefits, and what are the problems that it solves.
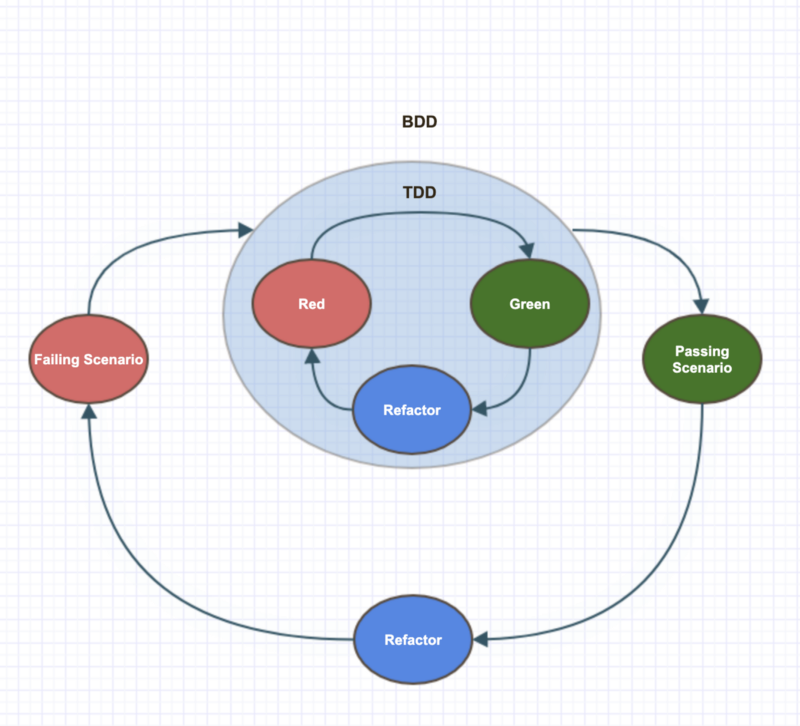
People occasionally tend to compare BDD with TDD, leading to the common misconception that as long as you are implementing (business-oriented) tests before actual coding, then you are practicing BDD. That’s actually a small part of it. Before you start formulating and implementing your acceptance tests, you have to understand the needs of your end user and how you are going to deliver them the best solution. This is basically the core of BDD: the bridge between business requirements and technical specification starts here.
As with all Agile practices, there are many ways to apply BDD Discovery depending on the reality of your business, company, team, etc. While we based ourselves mostly on The BDD Books, we will explain what is our approach to Discovery within our context, namely, what tools we use, how we organize and name the sessions, who participates, etc.
To sum up, Discovery should be a collaborative activity that is capable of picking a user story and exploring it until a shared understanding is reached. The main technique used to achieve this is called Example Mapping.
Example Mapping
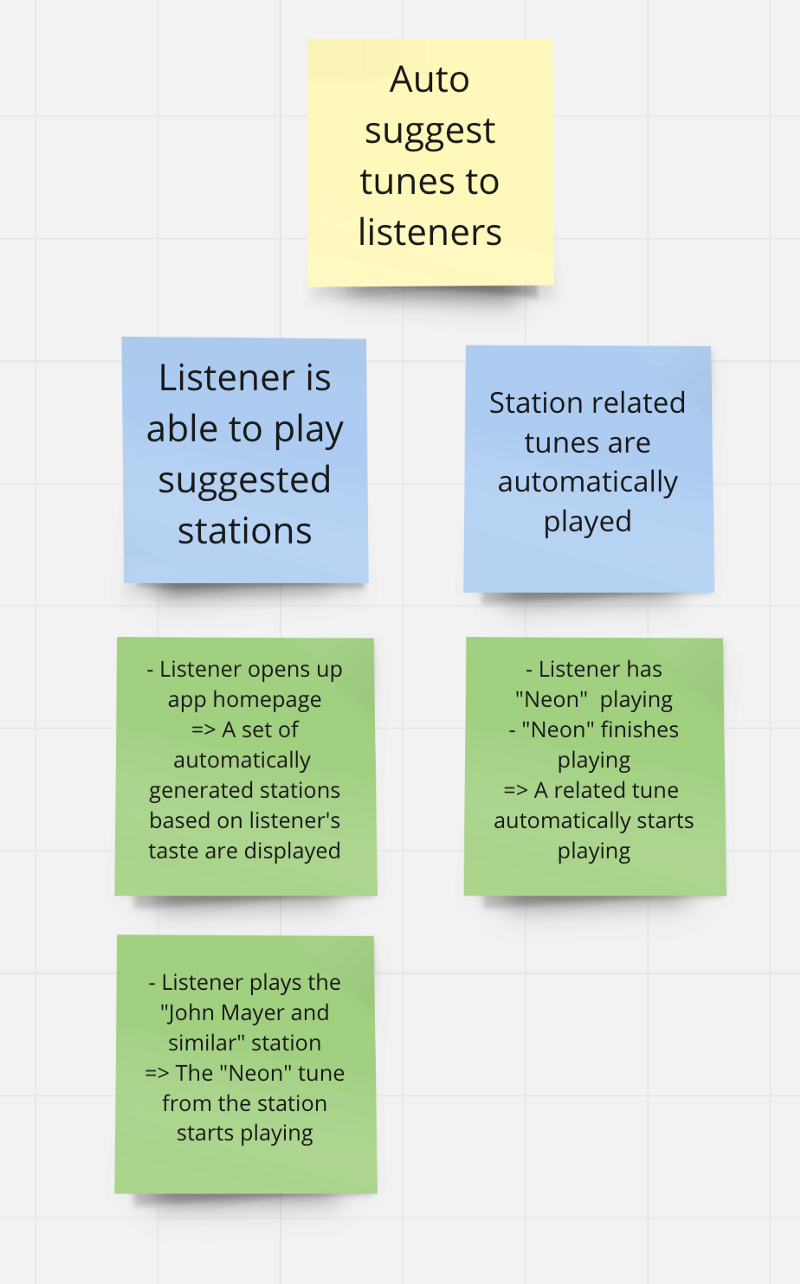
The Example Mapping consists in getting the team together to discuss the business requirements of a story using rules and concrete examples represented by cards of different colors placed in a visual board:
- User story: Represented by a yellow card, can be split and reorganized during the course of the example mapping.
- Rules: Represented by blue cards, they are statements that bring a specific business requirement, similar to Acceptance Criteria.
- Example: Represented by green cards, they illustrate each rule by describing a concrete case of a user interacting with the application.
- Loose Ends: Represented by red cards, any questions or assumptions that appear during the discussion and need to be addressed later.
To start, have the Product Owner (or someone that was involved in the topic analysis) give a brief explanation of the user story and guide the discussion. It doesn’t matter the order to achieve the final goal, sometimes the rules can be defined first or even pre-defined, and sometimes the story is vaguer and it makes sense to start exploring the examples of usage first, and then identify the rules based on that. After a consensus is reached for each rule you should move to the next one, there is no need to explore a lot of different examples and corner cases (there will be time for that), just enough for everyone present to be on the same page.
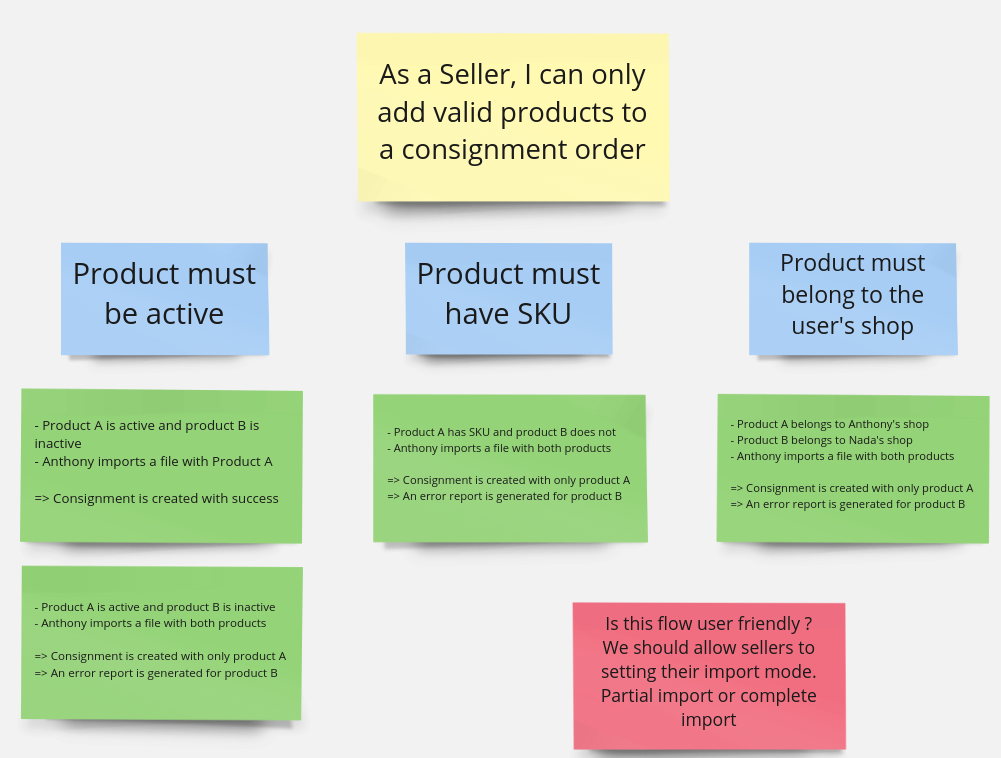
In the above example, a seller trying to create a consignment order has to follow specific rules regarding the products that can be included in his request.
- You can see that the first example of the first rule is a simple success scenario where they import a valid product and everything goes well.
- After this first example is discussed, it also becomes clear to everyone that in case it was an invalid product, there would be an error and the consignment wouldn’t be created, so the team finds no need to write this example now.
- However, one of the team members ask: “What if they import a lot of valid products and only one invalid, should we fail the entire request?”. The team decides it’s better to still create the consignment with the valid products, and generate a report to check the failed items, so they write the second example.
- This behavior is replicated for the other rules as well.
- Then another person says: “But let’s imagine the other way around, they import a file with lot’s of invalid products and only one valid, in this case, I think it wouldn’t be worth it to create the consignment with just one product, the seller would prefer instead to review the errors and try again after validating their products.”
- Someone then suggests: “What if the seller was able to choose an import mode, one that would succeed with any valid product and another that only succeeds if all products are valid?”. Seems like a good idea, but the team doesn’t have a definitive answer for it now, and it also seems to be out of scope, so the team writes a red card with this loose end to be discussed in the next session.
How Discovery was incorporated in our process?
Before BDD, we already had a well-established process in place based on Scrum, but that didn’t mean that we had to abandon the benefits of any of our previous practices, we just needed to adapt a little bit.
At the beginning of a topic, instead of having a big meeting in order to define, discuss and estimate all the user stories, we broke it down into smaller sessions where we would perform the example mapping for one or a couple of stories. We called them Business Workshops. We found that Business Workshops also replaced the need for “Grooming” when combined with a Tech Workshop, which is also story-oriented, a moment when you can discuss more technical aspects and solve loose ends that came from the Example Mapping if need be. Those workshops are done ideally several times a week, on-demand, and they are not meetings but rather working sessions as the name suggests.
Who participates?
To enjoy Discovery benefits the most, the whole team should ideally participate, but if not possible, we should have at least what we call the “Three Amigos” (business, development, test). Having people with different roles in the session brings different perspectives to the table. For example, a Product Owner might be more focused on fulfilling the business goals, while a developer will think about the technical implications of the feature, while a tester will challenge the feasibility of the rules. That doesn’t mean that those 3 are the only roles that can participate in those sessions, if there are more roles in your team (ex. UX/UI) for sure they will bring value to the discussion and also have more context to do their work correctly afterward. Remember that BDD is a bridge between the business requirements and the software itself, so it’s fundamental that someone from the business is involved at least on the Discovery part.
What tools do we use to accomplish the final result?
For Example Mapping, we use Miro, a platform for visual collaboration where you can build a virtual board. If your team doesn’t work remotely, you can even opt for a physical board with post-its. The result is then moved to each user story on JIRA with the following format:

This will serve as the base for the next step of the BDD process, the Formulation of acceptance tests.
Results / what changed / what benefits we observed
After some time of practicing Example Mapping, we observed these main benefits:
- Shared Understanding: First of all, it’s faster to reach a shared understanding. It’s easy to get everyone on the same page about your requirements when you direct the conversations using concrete examples and have your team thinking about the goal from the user’s perspective. Not only that, but shared understanding also means that your team will be progressively creating an ubiquitous language, multiple business terms that might mean the same thing will start to be standardized, while terms that have multiple meanings will be broken down into different ones. This will help eliminate confusion as everyone can quickly understand what we are talking about from a specific term.
- Quality of Conversations: Another nice benefit that we noticed was that the quality of our conversations got better, and not only during Example Mapping, but every other conversation/meeting tends to have a clearer scope and less entropy, mostly because we learn to separate business conversation from technical conversation.
- QA Shift Left: Last but not least, there is the shift left on QA. This is a movement where testing should be thought and done at the early stages of development, because the sooner you detect problems with your code, or even with your requirements, the sooner you can react to it and prevent it from reaching later stages of the lifecycle, where fixing them would cost more. Our team already had this mindset from a tech perspective, but BDD Discovery takes it further by involving the QA in business discussions from the very beginning of the process.
Tips
To close up, here are some tips that we find very helpful to follow while doing Example Mapping:
- Keep the sessions short (max. 30 minutes) to maintain engagement.
- The Example Mapping for a specific story should obviously be done before the development starts, but not so much in beforehand to avoid forgetting what was discussed. If you use Scrum, try to be one sprint ahead (Works well with 1 week sprints).
- Write the examples in a free language, don’t use Gerkhin at this point or any other way to structure the written language. The goal is throughput, i.e., reach the shared understanding quickly. The Formulation step is where the scenarios will be transformed into a structured language.
- Avoid discussing technical aspects.
- Every loose end should have an owner to follow it up afterward.
- Bring some pre-defined candidate rules. During the discovery they can be changed, new ones can be found, and the story can be split into multiple ones, but it helps to have a base for the discussion.
- Do not bring pre-defined examples though, it takes away the goal of collaborative thinking.